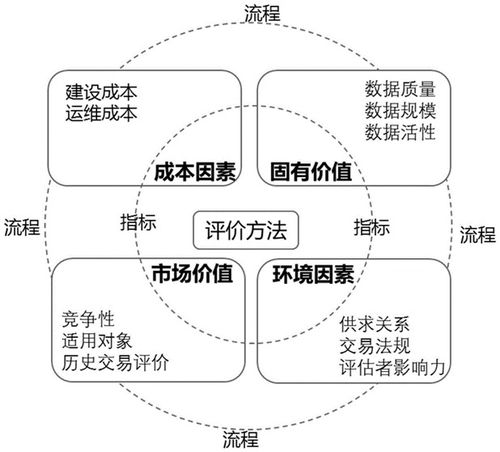
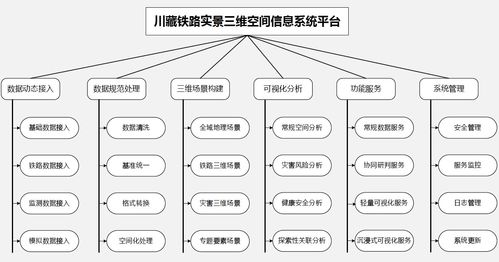
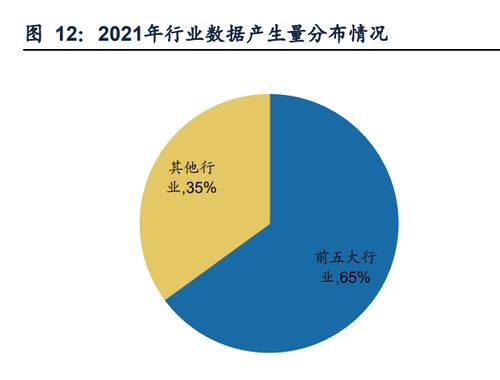
数据海洋的巨轮 探索全球最大的储存服务器与配套支持服务

在当今这个数据爆炸的时代,全球每日产生的数据量高达数百亿GB。为了承载这些数字世界的‘记忆’,数据中心和超大规模储存服务器应运而生。最大的储存服务器究竟是什么?它背后又依赖着怎样复杂的数据处理和存储支持服务生态呢?
需要明确一个概念:所谓‘最大的储存服务器’并非指单一的物理机柜或设备。在商业和科技领域,它通常指向由科技巨头运营的、规模达到‘Exabyte’(EB,即10亿GB)级别甚至‘Zettabyte’(ZB,即万亿GB)级别的超大规模数据中心集群。例如,谷歌、亚马逊AWS、微软Azure和Meta(原Facebook)等公司运营的数据中心,其总存储容量难以精确公开,但普遍被认为位居全球前列。这些设施并非一台服务器,而是由数百万台服务器节点、网络设备和存储阵列通过高速网络连接构成的分布式系统。一个代表性的例子是Meta的‘Prineville数据中心集群’或微软的‘Azure数据中心区域’,它们的设计目标就是提供近乎无限的、可弹性扩展的存储容量。
支撑这些庞然大物运转的,是一整套极其复杂和精密的数据处理与存储支持服务体系。我们可以将其分为几个核心层面:
- 硬件基础设施层:这是存储的物理基石。它包括:
- 海量存储介质:从高密度机械硬盘(HDD)到高速固态硬盘(SSD),乃至前沿的存储级内存(SCM),形成分层存储体系,以平衡成本、容量和性能。
- 定制化服务器与机架:为了追求极致的能效和密度,巨头们往往自主设计服务器主板、供电和散热系统,将成千上万的硬件单元高效封装。
- 网络神经系统:包括叶脊网络架构、光纤通道以及最新的RDMA技术,确保数据在数百万个组件间以微秒级速度流动。
- 软件与系统层:这是将硬件转化为智能服务的大脑。
- 分布式文件系统:如Google File System(GFS)及其开源仿制品Hadoop HDFS,或是更现代的Ceph、GlusterFS等,它们将物理上分散的磁盘抽象为一个统一的、容错的巨量存储池。
- 数据处理框架:以MapReduce、Apache Spark、Flink为代表的框架,允许对PB级数据进行并行分析和计算。
- 资源编排与调度:Kubernetes等容器编排平台,以及像Borg(Google)、Apache YARN这样的集群管理系统,负责高效分配计算和存储资源。
- 数据管理与服务层:这是直接面向用户和应用的接口。
- 数据库服务:涵盖关系型(如Amazon Aurora)、NoSQL(如Google Bigtable、MongoDB Atlas)和图数据库等,提供结构化和非结构化数据的存储与查询。
- 对象存储服务:如Amazon S3、Azure Blob Storage,它们已成为互联网上海量非结构化数据(图片、视频、备份)的事实标准存储。
- 数据湖与数据仓库:如Snowflake、Databricks、Google BigQuery,支持对海量数据进行复杂的交互式分析和商业智能处理。
- 运维与支持保障层:确保系统7x24小时稳定可靠。
- 自动化运维:通过AIops(智能运维)实现故障预测、自动修复和资源优化。
- 安全与合规:包括全链路加密、严格的访问控制、数据脱敏以及满足全球各地(如GDPR)的合规要求。
- 能效与冷却:采用自然冷却、液冷等尖端技术,并利用AI优化电力使用效率(PUE),以控制巨大的能耗成本。
因此,当我们谈论‘最大的储存服务器’时,实质上是在谈论一个由尖端硬件、革命性软件和全球性运维网络共同构成的、不断进化的数字基础设施生态。它的目标不仅是‘存储’,更是为了实现对海量数据的高效‘处理’、‘洞察’和‘价值提取’。随着量子计算、DNA存储等前沿技术的发展,数据存储的形态与规模还将继续被重新定义,但支撑其运行的服务生态——可靠、智能、可扩展——将始终是数字文明不可或缺的基石。
如若转载,请注明出处:http://www.51xmlong.com/product/44.html
更新时间:2026-06-19 03:52:37